Representation of Words
- atomic units: represented as indices in a vocabulary
- simplicity, robustness, better than complex systems
- no notion of similarity between words
- no pre-training: data for some special task are limited (speech recognition)
\(\)
- Distributed representations
- neural network language model (NNLM)
- other followers of NNLM
- Word2vec
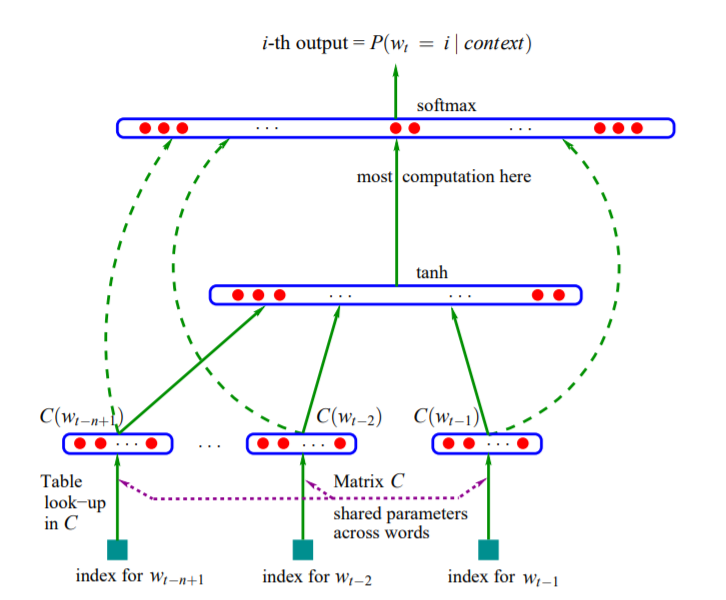
NNLM
1 | |
Objective function: \(L=\frac{1}{T} \sum_{t} \log f\left(w_{t}, w_{t-1}, \cdots, w_{t-n+1} ; \theta\right)+R(\theta)\) where $f\left(w_{t}, w_{t-1}, \cdots, w_{t-n+1} ; \theta\right)=\hat{P}\left(w_{t} | w_{1}^{t-1}; \theta\right)$ is the probability that given $w_{t-1}, \cdots, w_{t-n+1}$, the model can predict the right word $w_t$. $R(\theta)$ is a regularization term.
Computational complexity: \(Q=N\times D+N\times D\times H + H\times V\)
Here we should have a rough estimation about the scale of each number:
1 | |
It looks like that the dominator of $Q$ should be $H\times V$, however, a hierarchical softmax method can reduce $V$ to ideally $log_2(V)$. Then the dominant will become $N\times D\times H$.
This method is slow for the existance of the non-linear hidden layer. In 2013, Mikolov et al. showed that the hidden layer is not necessary and provided another model called Word2vec.
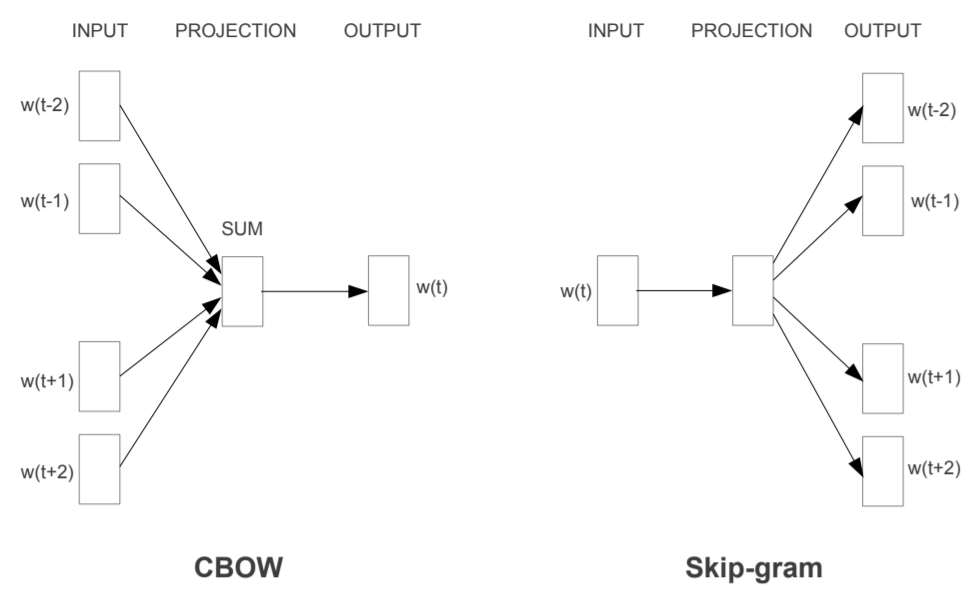
Word2vec
The method has two distinct model: CBOW and skip-gram. They share common idea that we don’t need a extra hidden layer, but use the word vector to do prediction directly.
Objective function
The objective is mostly the same as NNLM. Note a difference that NNLM predict a word $w_t$ using its previous words, while the CBOW model predict word $w_t$ using both previous words and subsequent words.
continuous bag-of-words (CBOW)
- bag-of-words
- any word is represented as a ont-hot vector with $V$ dimensions
- a sentence, or a sequence of words is represented as the sum of words included \(\)
- continuous bag-of-words
- any word is represented as a continuous vector (distributed representation)
- a sentence, or a sequence of words is represented as the sum of words included
-
computational complexity \(Q=N \times D+D \times \log _{2}(V)\) compare with it in NNLM, the dominating term $N \times D \times H$ disappeared because Word2vec removed the hidden layer.
- CBOW model works better in smaller scaled data.
skip-gram
- predict context words using only one word
- according to the distance to the input word, the output word in weighted through biased resampling
- computational complexity \(Q=C \times\left(D+D \times \log _{2}(V)\right)\) did not understand the $C\times D$ part
- works better in larger scaled data
tricks
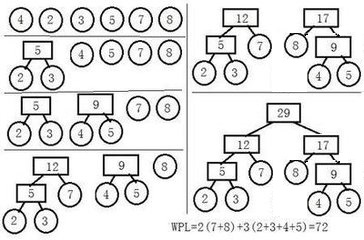
hierarchical softmax
Use a Huffman tree to assign short binary codes to frequent words. The tree will be constructed as below:
1 | |