In [1]:
%matplotlib inline
%load_ext autoreload
%autoreload 2
%load_ext line_profiler
In [2]:
import scanpy as sc
import random
from unicoord import scu
from unicoord.visualization import draw_loss_curves
import torch
from line_profiler import LineProfiler
In [3]:
sc.settings.verbosity = 3 # verbosity: errors (0), warnings (1), info (2), hints (3)
sc.logging.print_header()
# sc.settings.set_figure_params(dpi=80, facecolor='white')
sc.settings.set_figure_params(vector_friendly=False)
load hECA lung data¶
In [21]:
adata = sc.read_h5ad('h5ad/Lung.Adult.pp.h5ad')
In [22]:
sc.pl.embedding(adata, 'X_umap',legend_loc='on data', legend_fontsize=10,
color=['leiden','donor_id','seq_tech','cell_type'], ncols=2)
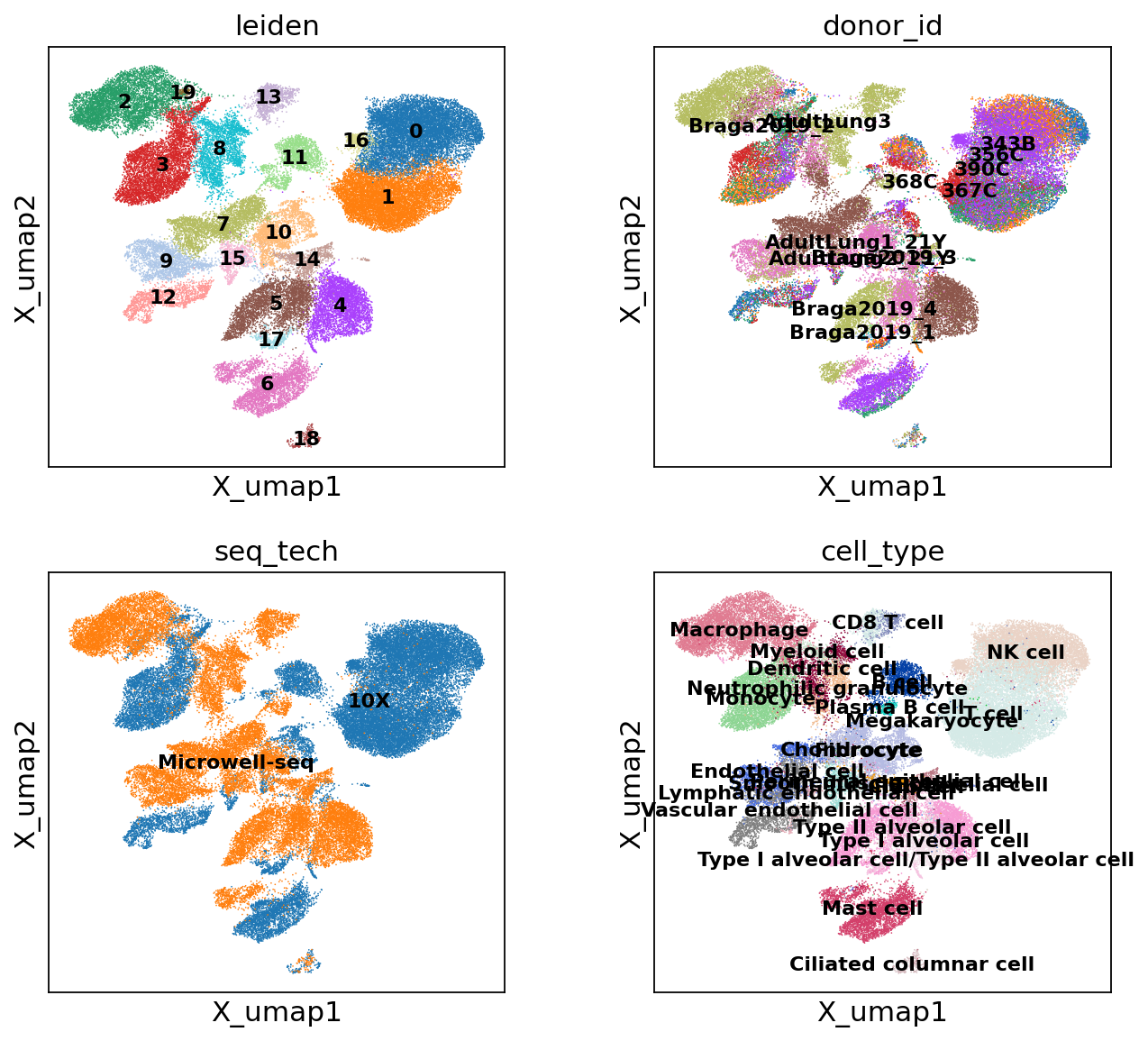
In [5]:
adata = adata.raw.to_adata()
sc.pp.normalize_total(adata, target_sum=1e4 ,exclude_highly_expressed= True)
sc.pp.log1p(adata)
adata
Out[5]:
In [6]:
adata.obs.donor_id.value_counts()
Out[6]:
In [7]:
adata.obs.seq_tech.value_counts()
Out[7]:
supervise batch¶
In [8]:
scu.model_unicoord_in_adata(adata, n_cont=30, n_diff=0, n_clus = [],
obs_fitting=['seq_tech'])
In [9]:
scu.train_unicoord_in_adata(adata, epochs=100, chunk_size=20000, slot = "cur")
In [10]:
fig = draw_loss_curves(adata.uns['unc_stuffs']['loss'])
# if save_figs:
# fig.savefig(os.path.join(savePath, 'img', 'fig1_lossCurves.png'))
fig.show()
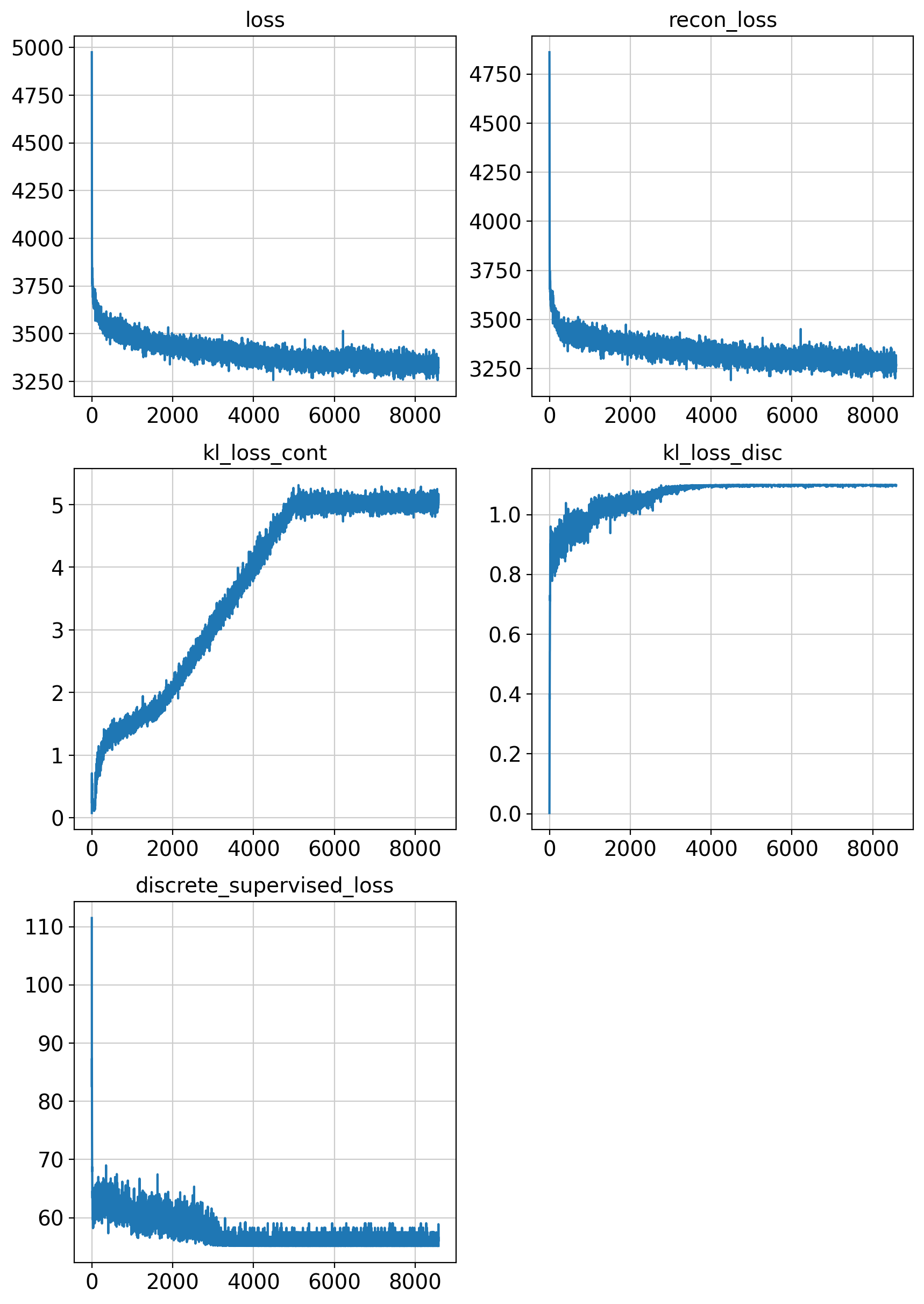
In [11]:
scu.embed_unicoord_in_adata(adata, chunk_size=5000)
sc.pp.neighbors(adata, use_rep='unicoord')
sc.tl.leiden(adata, resolution=0.5)
sc.tl.umap(adata)
In [12]:
sc.pl.embedding(adata, 'X_umap',legend_loc='on data', legend_fontsize=10,
color=['leiden','donor_id','seq_tech','cell_type'], ncols=2)

not supervise cell type¶
In [13]:
scu.model_unicoord_in_adata(adata, n_cont=100, n_diff=0, n_clus = [],
obs_fitting=[])
In [14]:
scu.train_unicoord_in_adata(adata, epochs=100, chunk_size=20000, slot = "cur")
In [15]:
fig = draw_loss_curves(adata.uns['unc_stuffs']['loss'])
# if save_figs:
# fig.savefig(os.path.join(savePath, 'img', 'fig1_lossCurves.png'))
fig.show()
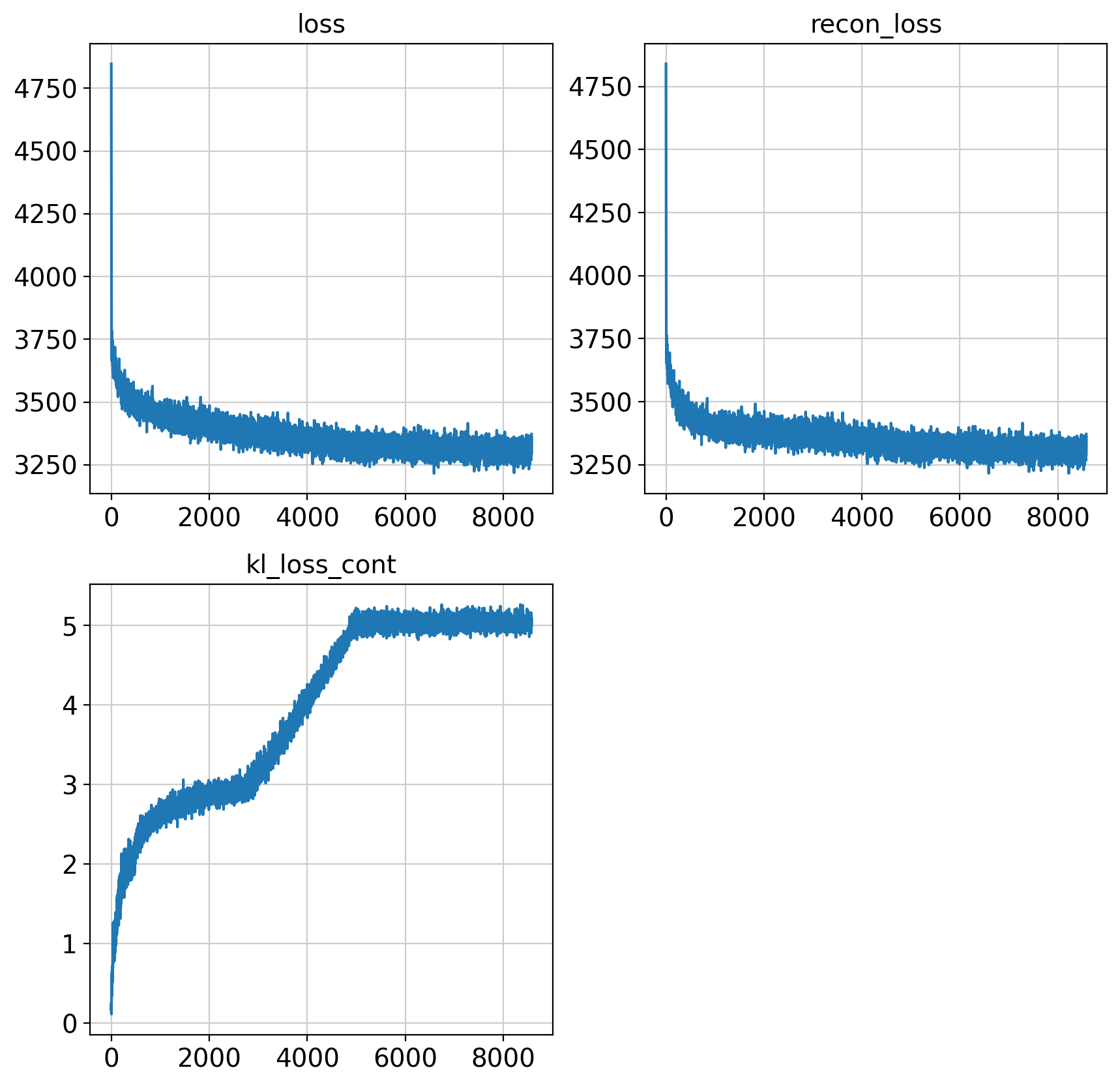
In [16]:
scu.embed_unicoord_in_adata(adata, chunk_size=5000)
In [17]:
sc.pp.neighbors(adata, use_rep='unicoord')
In [18]:
sc.tl.leiden(adata, resolution=0.5)
In [19]:
sc.tl.umap(adata)
In [20]:
sc.pl.embedding(adata, 'X_umap',legend_loc='on data', legend_fontsize=10,
color=['leiden','donor_id','seq_tech','cell_type'], ncols=2)
